Now hiring!
Public blockchains are increasingly becoming a credible infrastructure for financial services. Tokenized assets, stablecoins, collateral flows, fund units, and other financial instruments can be issued and transferred under deterministic rules, across borders, and through always-on settlement rails, whether on a Layer 1 (L1) such as Ethereum, or on Layer 2 (L2) scaling networks built on top of it. For institutions, this creates a path toward more programmable, interoperable, and efficient financial infrastructure.
Public rails also introduce a fundamental tension. The same transparency that makes blockchains verifiable also makes financial activity observable. Balances, transfers, counterparties, and interaction patterns can often be reconstructed from public data. For institutional use cases, this is not a minor limitation. Treasury positions, customer flows, trading strategies, and payment activity are commercially sensitive and often subject to regulatory and governance constraints.
Privacy therefore, cannot be treated as an optional feature for institutional blockchain adoption. Institutions need to preserve confidentiality of financial activity but they also need accountability for compliance control.
This post is the first in a series on Nethermind's privacy work. The series starts from a simple thesis:
Privacy is a core requirement for bringing real-world financial services onto public rails.
Different institutional use cases, however, require different privacy models. Some require confidentiality around individual asset transfers; others require private application logic, dedicated execution environments, or infrastructure that gives institutions stronger control over how sensitive data is processed and disclosed.
In the series, we will show how Nethermind builds privacy-preserving systems at each of these layers, across different institutional use cases.
This first post begins at the application layer. We map the main technical approaches to blockchain privacy and explain how different privacy models fit into the stack. We then focus on zero-knowledge proofs (ZKPs) as a pragmatic starting point. Concretely, we show how existing tokens can be deposited into a private pool, transferred privately, and withdrawn back to the public ledger while preserving public verifiability.
We close by outlining the importance for institutions of reconciling compliance requirements with privacy-preserving solutions deployed on public blockchains, a topic the next posts in this series will address.
No single mechanism delivers privacy on public blockchains. Different use cases require different assumptions about confidentiality, computation, trust, performance, compliance, and infrastructure control.
A useful way to map the space is to separate three questions:
These three lenses are largely orthogonal. The same primitive can serve different use cases, and the same use case can be deployed under different models. They are not entirely independent, though.
Three recurring privacy patterns are especially relevant in real-world use cases:
The main cryptographic primitives used to build privacy-preserving systems today, beyond standard encryption mechanisms, are:
Privacy models describe where privacy is enforced in the stack using one or more cryptographic primitives. The main deployment models are:
Choosing the right privacy model depends on the use case, the infrastructure trust assumptions (how privacy is achieved), and the visibility model (who sees the data).
At a high level:
The table below summarizes how the main privacy models apply to these use cases.
The matrix shows that there is no universal privacy solution, and choosing the right model depends deliberatey on the use calse and the acceptable trade-offs.
In this post, we start from a shielded-pool design for application-level privacy. Shielded pools are a pragmatic starting point: they are compatible with existing onchain assets (e.g., ERC-20s on Ethereum), preserve public verifiability, and demonstrate that private transfers can be engineered today on public blockchain infrastructure. They are not the whole privacy design space, but they are the first building block; across this Nethermind privacy series, we will explore the rest of the design space and show how privacy solutions can be delivered across the other models.
A "shielded pool" is a smart contract that escrow assets and maintains an encrypted, commitment-based representation of ownership (i.e., notes), while enforcing transfer correctness via ZK proofs.
The protocol follows a common pattern:
Before exploring protocol mechanics, we outline the core concepts, technological components, and roles within the system.
The UTXO model is a foundational concept in blockchain systems, like Bitcoin and Zcash. In this model, assets are represented as discrete outputs (i.e., UTXOs), each of which can be spent only once. These outputs are generalized as records that encapsulate value and ownership while hiding sensitive details from the public.
A user's balance is determined by the amount of "spendable" UTXOs (or notes) available in their wallet. Figure 1 shows a transaction between two users, Alice and Bob.
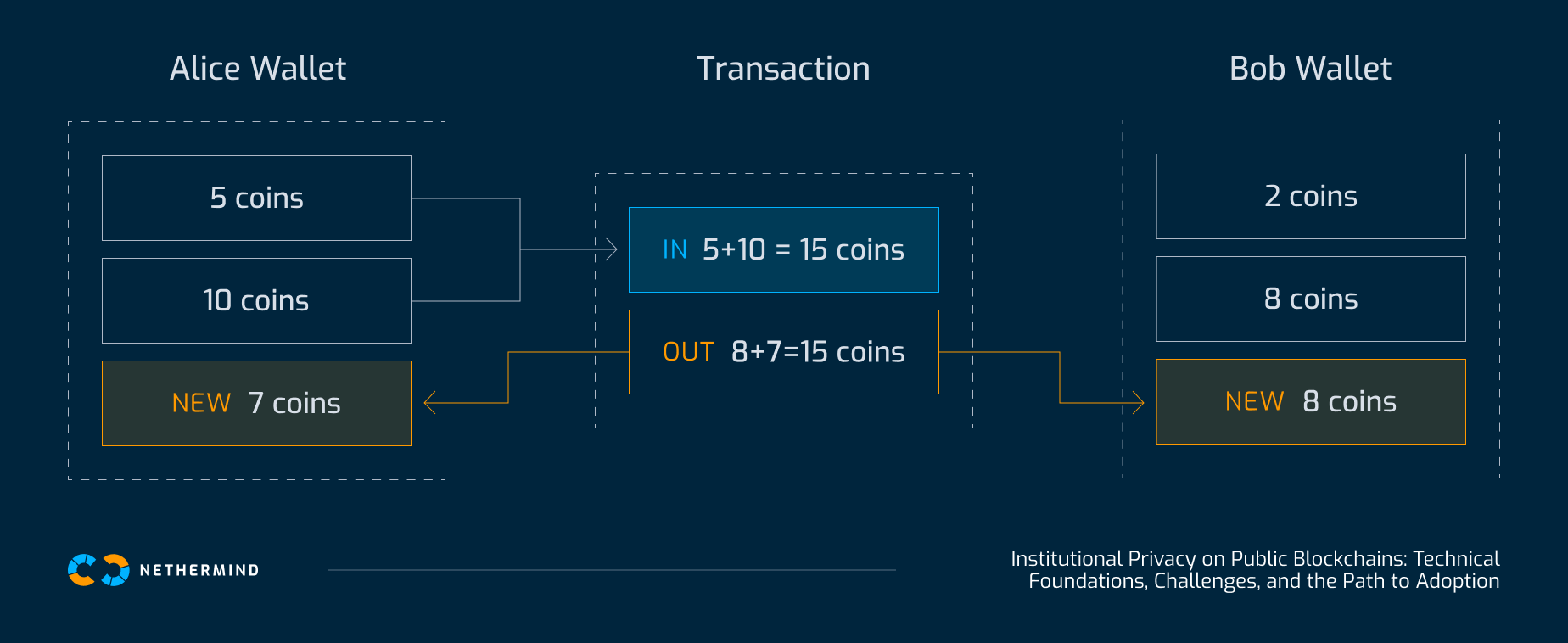
Alice owns two UTXOs that sum to 15 coins. Bob owns two UTXOs that sum to 10 coins. Alice wants to send funds to Bob. She consumes one or more of her existing UTXOs as inputs to a transaction and creates new UTXOs as outputs, one for Bob (the payment) and one for herself (as change). Each UTXO records an amount and a locking script (or public key), and ownership is transferred by satisfying the conditions of the previous output and creating new outputs for the recipients. This approach ensures that assets cannot be double-spent and that every transfer is independently verifiable.
In a transparent UTXO model, such as Bitcoin, all transaction outputs, inputs, and balances are publicly visible and directly linked to addresses, making it possible to trace asset flows and reconstruct user activity. In contrast, a privacy-preserving UTXO model like Zcash, hides sensitive details by recording only cryptographic commitments to UTXOs. Balances and transaction linkages remain confidential. Commitments cannot be linked to specific senders or recipients, and user balances are never exposed. Each UTXO is protected against double-spending by a unique nullifier, which is revealed only when the note is spent, preserving integrity without sacrificing anonymity.
A privacy-preserving UTXO model adapts the UTXO concept so that value and ownership stay confidential on a public chain. We first set out the properties and trust model, and then we present the underlying cryptographic components.
The protocol provides privacy and integrity using verifiable ZK proofs. There is no trusted third party required for core protocol security. Users trust that:
The core security and privacy properties of the protocol are:
Implementing a privacy-preserving UTXO model on a public chain requires different cryptographic components.
User Key Material: Users are assigned two types of cryptographic keys:
user_pk = hash(spend_sk). This public key is used in note commitments to ensure ownership and spending rights in a ZK circuit.
Notes: A note is the shielded equivalent of a UTXO.
Note = (
token, // token representation, e.g., an ERC-20 contract address
user_pk, // recipient address public key (derived from spending key)
v, // value, represents an amount of token
rcm // commitment randomness
)
The pool contract stores only a cryptographic commitment to each note in a Merkle tree; the leaves of the tree are note commitments cm = hash(token, user_pk, v, rcm), not the plaintext data. The tree root is updated each time a new valid note is appended.
Nullifiers: To prevent double-spending, each note has a unique nullifier. The nullifier is derived as a pseudorandom function of the note and the spending key.
nf = hash(spend_sk, cm)
When a note is spent, its nullifier is revealed and recorded onchain in the shielded pool smart contract; any attempt to spend a note with a previously used nullifier is rejected.
Encrypted Notes: When a note is created, its details are encrypted and emitted onchain (e.g., Ethereum's onchain event). Recipients use their viewing key to scan for and decrypt these encrypted notes, discovering new incoming notes without revealing their identity or balances to the public.
Proofs: ZKPs are used to prove, without revealing sensitive information, that a shielded transfer is valid according to the protocol rules defined in a ZK circuit, such as a program encoding the those rules. To generate a ZKP, the circuit runs over public inputs (visible data like the spending note commitments) and a witness (private data like the spending key).
Relayers: In a naive shielded pool design, the user who submits a transaction onchain must pay gas from a funded account, which can link their public identity to the shielded operation, hencedegrading privacy. Relayers are specialized intermediaries appointed to submit transactions on behalf of users, breaking the onchain link between the submitter's Ethereum address and the shielded action. The user constructs the proof and transaction payload offchain and hands it to a relayer, who broadcasts it and pays the fee. Typically, relayers are compensated through a small deduction from the paid fee. Relayers represent an additional trust component, as they can arbitrarily censor private transactions. For simplicity, we do not consider relayers in this post, but they remain an important component for achieving anonymity in production deployments.
Throughout the flow descriptions, we use the following nomenclature:
SPSC: The Shielded Pool Smart Contract deployed on a public chain.User: An entity interacting with the pool (depositing, withdrawing, or transferring).Sender: The user spending input notes in a shielded transfer.Receiver: The user for whom output notes are created in a shielded transfer.
We now proceed to describe the flows.
A deposit converts a public token amount into one or more shielded notes inside the pool. The user constructs the note commitments (cm_list) and their corresponding encrypted payloads (encrypted_notes), and generates a ZKP (proof) showing that the notes are well-formed and that their total value equals the deposited amount. The tokens are then transferred from the user's wallet into the pool's custody. Upon deposit, the pool verifies the proof and updates its local state by updating the commitments Merkle tree root.
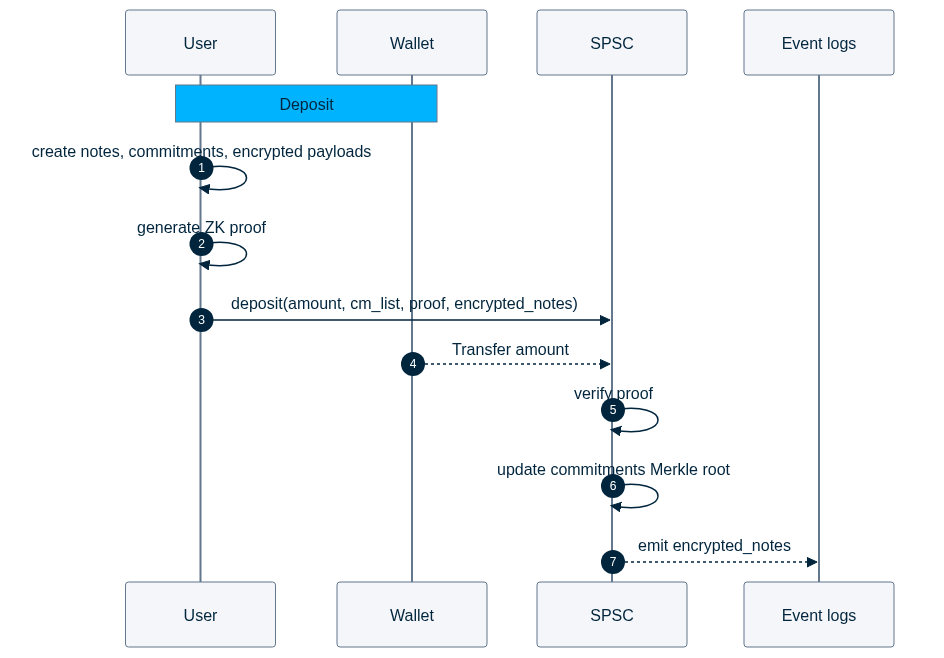
When interacting with a deposit, the amount, the depositing address, and the token are publicly visible. However, the proof hides how the deposited amount is split across notes, which public keys own them, and the randomness. An external observer can see that a deposit of a given amount occurred, but cannot determine how ownership is assigned inside the pool once the notes are created.
The proof takes as public inputs the commitment list, the deposit amount, and the token address. The witness provides private information such as the user's spending key, individual note values, and commitment randomness.
A shielded transfer moves value within the pool. The Sender spends existing notes by revealing their nullifiers and creates new output notes for the Receiver and, eventually, for change. The pool verifies that the nullifiers are unused, verifies the ZK proof, appends new commitments to the tree, and emits encrypted outputs for the recipient.
The ZK proof enforces a compact set of checks, all publicly verifiable. The proof asserts that:
A withdrawal exits back to the user's wallet. The user proves they are spending valid notes and that the withdrawal amount is consistent with inputs and outputs (including optional change); the pool then transfers tokens to a public recipient wallet after successful verification.
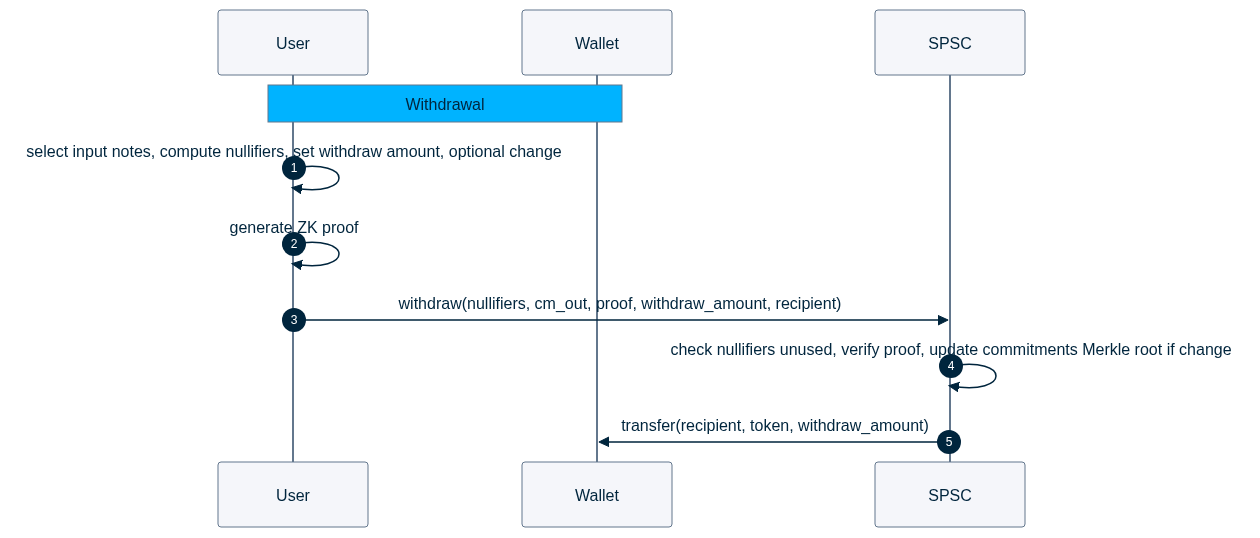
The withdrawal amount, the recipient address, and the token are publicly visible onchain; any external observer can see that tokens have been transferred out of the pool to the recipient's wallet. The SPSC is also updated with the newly revealed nullifiers and the commitments Merkle root, if change notes are created. The proof hides which input notes were consumed, their individual values, the total balance of the spender, and the structure of any change notes.
To show practicality, we implemented a shielded pool protocol for ERC-20 tokens on public Ethereum and benchmarked it with real flows. The results show that private transfers are practical today; ZK proving a transfer takes roughly 1.5 seconds on commodity hardware and settles for under a dollar on Ethereum L1. Our implementation is open source and available here.
Measured on a MacBook Pro M3 (18 GB RAM). Every ZK proof in our setup carries four input and four output notes, which keeps the circuit, proof size, and gas cost identical across deposits, transfers, and withdrawals.
Performance. A client generates a complete shielded-transfer proof that spends four notes in roughly 1.5 seconds end-to-end, all of it spent on the ZK proof generation and offchain pre-submission validation. It runs entirely in the browser, so a user needs no specialized prover infrastructure to transact privately.
Cost. Onchain, verifying a transfer costs about 301K gas with a constant 256-byte proof, stable across deposit, transfer, and withdrawal. At market conditions around the time of writing (roughly 1.5 gwei gas price and ETH at about $2,000), that works out to about 0.00045 ETH or about $0.90 per private transfer on Ethereum L1. On an L2, where calldata and gas are far cheaper, the same operation costs a small fraction of that.
These results show that a private ERC-20 transfer is practical on Ethereum: it proves in seconds and settles for well under a dollar on L1 (and a fraction of a cent on L2). The cryptography is not the
The bottleneck is not the proving time or the gas cost. It is everything around them. Achieving privacy at the application level required us to build far more than a smart contract. A working shielded pool meant implementing, from scratch:
Reproducing this end-to-end (circuits, contracts, prover tooling, indexer, and wallet integration) represents a significant engineering and audit burden, and on its own a major barrier to entry.
Nethermind is committed to lowering this barrier. Institutions should not have to assemble circuits, contracts, and key management themselves; Nethermind delivers privacy solutions across different layers of public chain ecosystems with the goal of reducing entry barriers and supporting broader blockchain adoption.
With shielded pools, we showed how privacy can be achieved on public blockchains. These protocols also introduce regulatory challenges that undermine institutional adoption. The case of Tornado Cash illustrates this tension clearly. Tornado Cash is a mixer built on cryptographic primitives similar to shielded pools. The protocol is fully permissionless and provides anonymity without governance. From a regulatory perspective, this made it an ideal tool for illicit activity. Its sanctioning by the U.S. Treasury in 2022 demonstrated how quickly privacy infrastructure can become an enforcement target when it lacks credible compliance mechanisms.
For institutions that operate under regulatory constraints, the takeaway is that privacy on public chains is achievable, while full anonymity is not a viable operating model. Privacy models should enforce compliance safeguards by design:
Beyond these compliance dimensions, standardization is an equally important barrier. Institutions prefer standardized approaches with clear governance and broad ecosystem support. Frameworks like CMTA and ERC-3643 have shown how standardization accelerates institutional adoption for tokenized securities.
Private transfers are practical on public chains today. The shielded pool protocol above proves in seconds and settles for well under a dollar on L1. Technical feasibility, though, is only half the story. Anonymity without control is not an institutional solution. Regulated entities need compliance mechanisms such as selective disclosure, access control, and asset-level governance.
Standardization and tooling matter just as much. Today, privacy solutions often rely on different trust models, integration patterns, and user experiences. For institutions accustomed to standardized rails, this fragmentation is itself an adoption barrier. Without common interfaces and deployable patterns, privacy-preserving infrastructure risks remaining a set of bespoke experiments rather than becoming a shared layer.
Nethermind is working to address this challenge. Privacy and compliance on public chains cannot be solved by a single product or isolated protocol. In a multi-chain ecosystem where assets and applications span multiple public ledgers, privacy must become a cross-domain capability across the public-chain stack.
Nethermind is building the protocols, tooling, and deployment patterns needed to make this practical for institutions. The objective is to reduce the complexity of privacy-preserving solutions, so institutions can move onchain faster while remaining aligned with their regulatory and operational obligations.
The next post moves from private transfers to standardized, compliant private transfers: we present a privacy-preserving payment system for the Stellar network, built on shielded pools with added auditing and compliance functionalities. From there, the series broadens across the stack. For application-level privacy and compliance, we will present a shielded pool implementation that remains backward compatible with existing token standards (such as CMTA and ERC-3643); we will then show how privacy-preserving solutions can be implemented on L2 infrastructure, either using privacy-preserving rollups or adopting custom private execution environments. Finally, we will conclude this series with an analysis of the trade-offs across the presented solutions, the remaining open challenges, and how Nethermind and its ecosystem partners are working to address them.
The Leading Engineers of Blockchain Infrastructure
Nethermind © 2026
.svg)
.svg)

.svg)

.svg)
.svg)



.svg)
.svg)
.svg)
.svg)






.png)









.svg)